ChatGPT besticht durch seine Fähigkeit, auf jede erdenkliche Frage aus jedem vorstellbaren Themengebiet eine – meist passende – Antwort generieren zu können. Datengrundlage sind dabei Unmengen von Webseiten und Texten, zum Beispiel aus Wikipedia. Wie können nun aber Fragen zu Texten beantwortet werden, die dem System gar nicht bekannt sind?
ChatGPT soll Fragen zu eigenen Texten beantworten
Bereits im Beitrag Text Mining: Das Wichtigste in Kürze aus dem März 2017 hatte ich mich mit Fragen aus dem Bereich Text Mining beschäftigt. In einer Sammlung von Texten – dem Korpus – sollten zum Beispiel die Besonderheiten eines jeweils gewählten Textes im Vergleich zu den restlichen Texten herausgearbeitet werden.
Dabei hatte ich es mit einem “Bag of words”-Ansatz versucht. Mittlerweile sind die verwendeten Methoden ausgefeilter und vor allem die Large-Language-Modelle (LLM) – angewandt etwa in Gestalt von ChatGPT – beherrschen seit Monaten die Schlagzeilen und werden von dort auch nicht so schnell wieder verschwinden. Unser Consulting-Team hatte bereits in ChatGPT in der Praxis: Anwendungen und Einsatzmöglichkeiten einen ausführlichen Überblick gegeben.
Nun wollte ich ein ausgewähltes Problem behandeln und hatte mich gefragt, wie man ChatGPT dazu bringen kann, Fragen zu Texten zu beantworten, die ChatGPT gar nicht kennt:
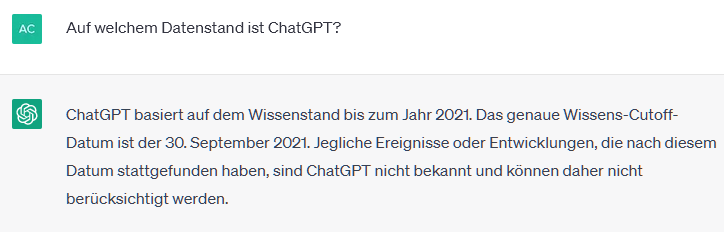
Keine Ahnung von Ereignissen nach September 2021
ChatGPT (ausprobiert auf chat.openai.com) behauptet nämlich von sich selbst, auf dem Stand vom 30.9.2021 zu sein.
Somit kann ChatGPT zu speziellen Ereignissen nach September 2021 keine Fragen vernünftig beantworten, da das dazu benötigte Wissen einfach nicht vorhanden ist. Ein ähnliches Problem besteht, wenn sich zwar etliche Seiten mit einem Thema beschäftigen, wir aber die Behandlung der Frage wie auf einer ausgewählten Seite dargestellt wünschen.
ChatGPT auf einer Sammlung von Texten
Als Anwendungsbeispiel soll ChatGPT Fragen beantworten, die wir zu einer gegebenen Menge von Texten stellen wollen. Diese können beispielsweise die Webseiten einer Domain sein. Auch eine Sammlung von Dokumenten könnte die Datenbasis bilden. Dabei sind auch Vertraulichkeit und Datenschutz zu beachten, falls wir diese Texte ChatGPT zur Verarbeitung anvertrauen wollen.
In Text Mining: Das Wichtigste in Kürze hatte ich alle 49 Blogbeiträge vor dem März 2017 in den Korpus aufgenommen. Da wir die Antworten überprüfen wollen, bietet es sich nun an, die 72 Beiträge ab April 2017 bis April 2023 als Datenbasis zu verwenden. Diese sind öffentlich zugänglich und somit ist hier die Arbeit mit ChatGPT unkritisch.
Auch wenn der Webcrawler von ChatGPT die Beiträge bis September 2021 möglicherweise besucht hat, ist ein Verweis auf eine spezielle Webadresse schwierig. Ein Bezug auf eine Webadresse kann wohl nur dann sicher funktionieren, wenn diese im Text mit dieser Adresse auch auftaucht.
ChatGPT gibt zwar auf der offiziellen Seite auch auf Wunsch Links zu den Antworten aus, aber es bleibt unklar, ob diese noch aktuell und wirklich vorhanden sind. Ich habe Fälle gesehen, bei denen Aussagen mit Links zu nicht existierenden, erfundenen Veröffentlichungen untermauert wurden.
Es wird aber intensiv geforscht, Quellenangaben in die Antwort einzubauen. Die Firma Microsoft, die ja mit Open AI eine Partnerschaft eingegangen ist, gibt beispielsweise in ihrer neuen Variante der Suchmaschine Bing bereits Quellen in Form von Links an.
Idee des Ansatzes
Wir wollen nun erreichen, dass wir zu einer gestellten Frage relevante Informationen – basierend auf unserem Korpus – erhalten. Dies könnte beispielsweise eine Auflistung von passenden Dokumenten zur Anfrage sein oder wir erhalten bereits eine direkte kurze Antwort, ohne dass wir das zugehörige Dokument öffnen müssen.
Dazu muss man wissen, dass intern jeder beliebige Text (selbst ein einzelnes Wort!), aber auch jede beliebige Frage als hochdimensionaler reeller Vektor repräsentiert wird. Bei hier im Beispiel verwendeten Modell “text-embedding-ada-002” sind es 1536-dimensionale reelle Vektoren. Jedem Text und jeder Frage ist somit ein solcher Vektor zugeordnet (“Embedding”).
Nun steht ein Vektor stellvertretend für den thematischen Inhalt. Ähnliche Inhalte werden durch ähnliche Vektoren dargestellt.
Es reicht nun, einmalig für alle vorhandenen Texte die zugehörigen Vektoren zu ermitteln und lokal in einer Datenbank abzuspeichern. Kommt nun eine Anfrage, wird für diese Frage ebenfalls der Vektor ermittelt. Somit können wir dann für diesen Vektor die Abstände zu den Vektoren der Datenbank berechnen.
Diejenigen Dokumente mit den geringsten Abständen werden dann dem Anwender als relevant angezeigt.
Erweiterung in einem Tutorial von Open AI
Bei der Recherche, wie ich die nötigen Berechnungen am besten durchführen sollte, stieß ich bei Open AI auf ein Tutorial How to build an AI that can answer questions about your website. Hier wird mit Python ein solches System aufgebaut, das Fragen beantworten kann und zunächst genau so vorgeht, wie es mir vorschwebte. Für diesen ersten Teil wird nur ein Embedding-Modell (hier “text-embedding-ada-002 “), aber nicht ChatGPT selbst benötigt.
Wie man mit der API arbeitet, wird in der API-Referenz ausführlich erklärt.
Ich habe diese Befehle nun angepasst und in meiner Anaconda-Umgebung in einem Jupyter-Notebook ausgeführt.
Nachdem ein Webcrawler alle verlinkten Seiten einer Domain besucht hat, liegen die Inhalte der gefundenen Seiten als Textdateien in einem Verzeichnis. Bei mir sind es die 72 Forschungsblog-Beiträge ab April 2017, die ich mit ihrem Erscheinungsdatum als Namen abgelegt habe:
Sämtliche Blog-Texte versammelt in einem Verzeichnis
Die Inhalte der Texte werden nun ausgelesen und von überflüssigen Leerzeichen und Newline-Befehlen befreit. Hier sind nun die Textanfänge sichtbar:

Die Texte stehen nun in Python bereit
ChatGPT arbeitet nun nicht direkt mit den Wörtern, sondern mit Tokens, also Silben oder Teilen von Wörtern.
Tokens der Texte
Mit einem Tokenizer werden nun die Texte in eine Folge von Tokens verwandelt. Das folgende Histogramm zeigt die Verteilung der Anzahl der Tokens pro Text in Form eines Histogramms:
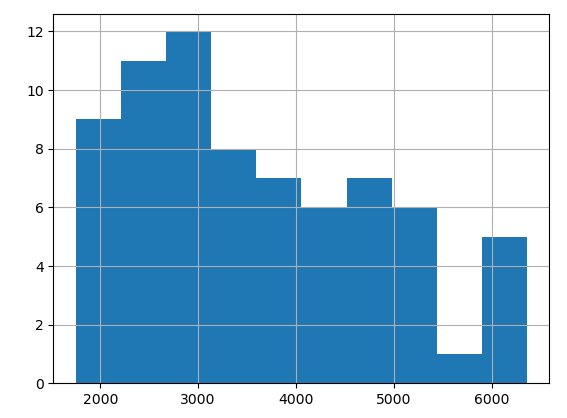
Ein Histogramm der Anzahl der Tokens
Möchten wir einen Text als Kontext einer Abfrage nutzen, darf er nicht zu viele Tokens enthalten. Die Fenstergröße ist beschränkt und hängt vom verwendeten Modell ab. Meine Blogtexte enthalten etwa 2000 bis 6000 Tokens pro Text.
Zerlegung in kleinere Textblöcke
Im Tutorial ist zwar eine maximale Grenze von 4097 Tokens für den Kontext aktiv, aber trotzdem werden die Texte in deutlich kleinere Blöcke von maximal 500 Tokens umgewandelt. Dies geschieht automatisch und logisch zusammenhängende Absätze können dabei möglicherweise getrennt werden. Natürlich wäre auch eine aufwändigere Aufteilung per Hand möglich.
Kürzere Abschnitte sind auch dann sinnvoll, wenn der Text mehrere Themen behandelt. Weiterhin wäre es auch möglich, überlappende Textabschnitte zu verwenden; die Textabschnitte müssen nicht zwingend disjunkt sein.
Nach diesem Schritt haben wir anstelle der 72 Texte nun 518 Textabschnitte (in Tokenform) zur Verfügung:
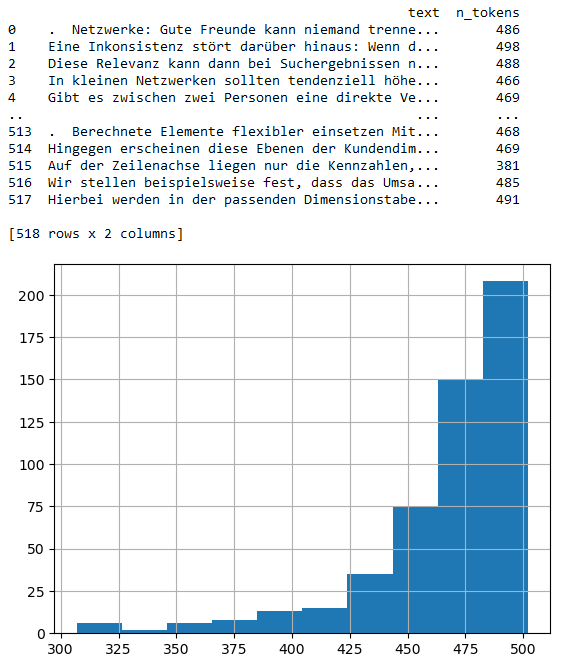
Textblöcke und Histogramm der Anzahl der Tokens
In den 518 Textabschnitten sind nun jeweils maximal 500 Tokens enthalten. Die letzten Einträge 513 bis 517 gehören beispielsweise zum letzten Blog-Artikel Berechnete Elemente flexibler einsetzen aus dem April 2023.
Embeddings
Zu jedem Textblock werden nun die Embedding-Vektoren einmalig ermittelt (das heißt, die Kosten hierfür fallen auch nur einmalig an!). Dazu wird das einfachste (und in der Anwendung billigste) Modell ‘text-embedding-ada-002’ eingesetzt. Wichtig ist nun, dass man bei der späteren Frage bei diesem Embedding bleibt. Die Embeddings unterschiedlicher Modelle passen nicht zueinander.
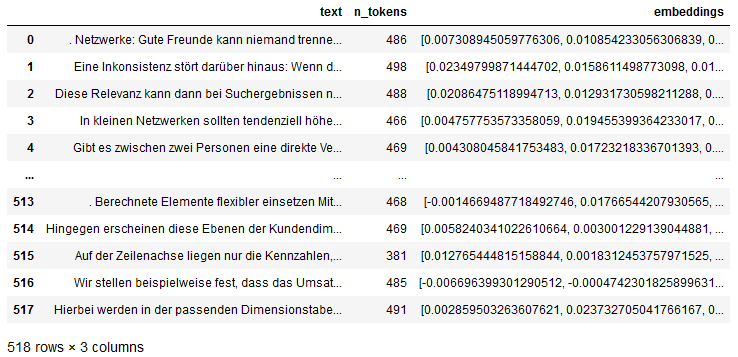
Textblöcke mit den Embeddings
In der letzten Spalte sieht man die ersten beiden Werte der 1536-dimensionalen reellen Embedding-Vektoren.
Bereit für einen ersten Einsatz
Nun können wir Fragen an die Engine stellen und uns die relevanten Textabschnitte zeigen lassen. Wie ermitteln zur Frage den zugehörigen Embedding-Vektor (wieder mit dem Modell ‘text-embedding-ada-002’!) und berechnen dann die Abstände zu den Vektoren der Textblöcke. Diese Abstände sortieren wir aufsteigend und zeigen die IDs der ersten Textblöcke an.
Fragen wir einmal beispielsweise “Wer nutzt eigentlich die DeltaApp?”:
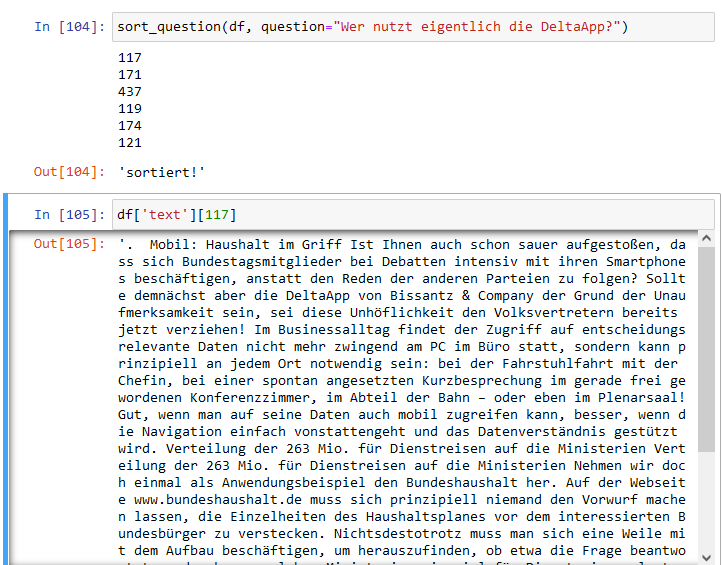
Wer nutzt eigentlich die DeltaApp?
Als ähnlichster Textblock (ID 117) wird der Anfang des Artikels Mobil: Haushalt im Griff eingeschätzt. Auf dem zweiten Rang liegt der Beginn des Artikels Mobil: Fahrt ins Glück.
Allerdings werden nur Verweise auf möglicherweise relevante Abschnitte vorgeschlagen. Man muss weiterhin die aufgelisteten Texte lesen, um zu prüfen, ob die Inhalte passende Informationen zur Frage enthalten.
Selbst die Suche nach einem Rezept für Käsekuchen führt somit auch zu einer Ergebnisliste:
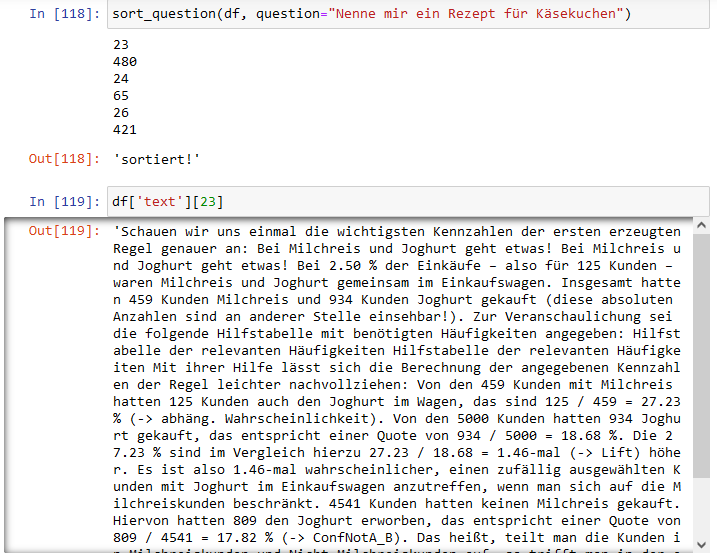
Nenne mir ein Rezept für Käsekuchen
Hier wird als passendster Artikel der zweite Textblock aus Analysen: Publisher or perish genannt, in dem ich anhand von Joghurt und Milchreis die Warenkorbanalyse erkläre. Joghurt kann ein Bestandteil eines Käsekuchens sein!
Auch der Textblock (ID 480) aus dem Artikel Inflationsrate und Verbraucherpreisindex enthält einen Abschnitt mit dem Satz “Besonders Fleisch- und Wurstwaren bei “Fleisch und Fleischwaren” bzw. Käse und Quark bei “Molkereiprodukte und Eier” sind die Ausgabentreiber im repräsentativen Warenkorb.”
Es wird somit immer einen ähnlichsten Blogbeitrag geben, der aber nicht zwingend die gestellte Frage/Aufforderung beantwortet.
ChatGPT mit Kontext
Das Tutorial How to build an AI that can answer questions about your website geht deshalb einen Schritt weiter und nutzt die gefundenen Textblöcke als Kontext für eine Anfrage an ChatGPT. Im bisherigen Ansatz wurde nur eines der zugrundeliegende Modelle – “text-embedding-ada-002” (um Texte als Embedding-Vektoren darzustellen) – verwendet, aber noch nicht ChatGPT selbst.
Damit der Kontext nicht beliebig groß wird, werden Textblöcke in der Sortierreihenfolge zum Kontext hinzugefügt, solange die Grenze von 1800 Tokens nicht überschritten wird. Da wir die Länge eines Blockes auf maximal 500 Tokens beschränkt hatten, werden ca. 3 – 4 Textblöcke zusammengefügt und als Kontext verwendet.
Die Textblöcke können dabei auch aus unterschiedlichen Artikeln stammen!
Schließlich wird bei der Anfrage vom Typ “Completion” der zusammengefasste Text in einem Prompt verwendet, der in der Form “Beantworte die Frage auf der Basis des untenstehenden Kontexts, und falls die Frage mit diesem Kontext nicht beantwortet werden kann, sage ‘Nichts gefunden!’ Kontext: xxx Frage: yyy Antwort:” aufgebaut ist.
ChatGPT soll also die Frage auf der Basis des übergebenen Kontexts so gut wie möglich beantworten. Übrigens setzen wir für die Erzeugung der Antworten das fähigere Modell “text-davinci-003” ein.
Fragen wir nun erneut nach einem Rezept für Käsekuchen, so reicht der Kontext für eine auf den Textblöcken basierende Antwort nicht aus:
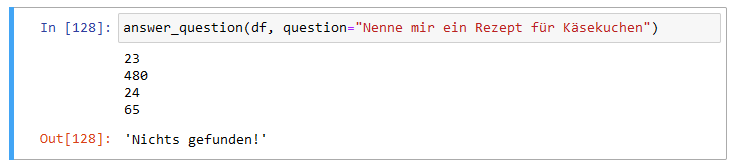
Nenne mir ein Rezept für Käsekuchen mit Kontext
Im Falle der Frage nach den Nutzern der DeltaApp erhalten wir die Antwort:
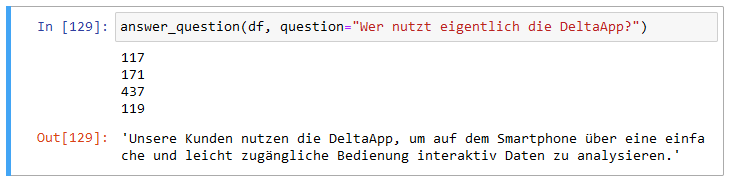
Wer nutzt eigentlich die DeltaApp? Unsere Kunden!
Es ist nicht direkt ersichtlich, welcher der vier Textabschnitte hauptverantwortlich für die Antwort ist. Ich vermute stark den dritten Abschnitt (ID 437) aus dem Artikel Interaktive Datenanalyse mit der DeltaApp.
Es sei angemerkt, dass die Lösung von Open AI die verwendeten Artikel gar nicht erwähnt, sondern die Antwort ohne weitere Zusatzinformationen ausspuckt.
Es wäre weiterhin zu klären, welche Rolle die Reihenfolge der Textabschnitte spielt. Falls sich widersprechende Aussagen zu einer Frage finden, hat möglicherweise der zuletzt hinzugefügte Textabschnitt mehr Gewicht, obwohl er eine geringere Ähnlichkeit zur Frage aufweist.
Dies ist aber nur eine Vermutung und wäre noch zu untersuchen.
ChatGPT mit eigenen Texten: Fragen der Robustheit
Ein Vorteil des Ansatzes ist, dass das System tolerant gegenüber Rechtschreibfehlern ist.
Fragt man etwa “Wie fungtioniert der Komparator?”, so erhält man trotzdem eine passende Antwort:
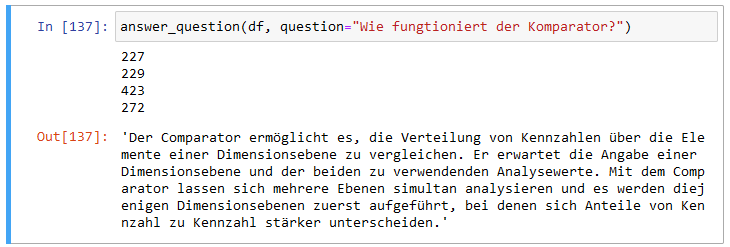
Wie fungtioniert der Komparator?
Dies ist eine Antwort aus dem Lehrbuch.
Man kann die Variabilität der Antwort über Parameter steuern. In der Default-Einstellung der Parameter kann das erneute Stellen einer Frage zu einer abweichenden Antwort führen:
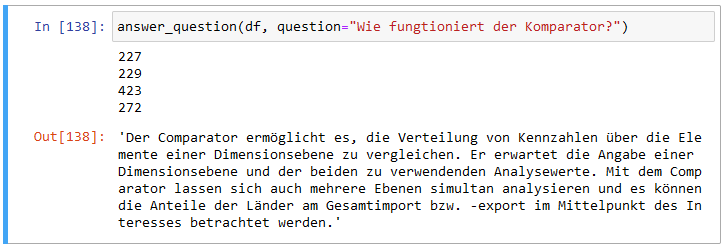
Wie fungtioniert der Komparator? (II)
Hier startet die Antwort wie im ersten Durchlauf mit einer allgemeinen Beschreibung, erwähnt dann aber – dabei stilistisch nicht ganz überzeugend – Eigenschaften, die nur für das konkrete Beispiel aus dem Beitrag Importe und Exporte in der Analyse gelten, aber keine Allgemeingültigkeit besitzen.
In eine ähnliche kleine Falle läuft man bei der Frage “Wie wird in Deutschland Strom erzeugt?”:
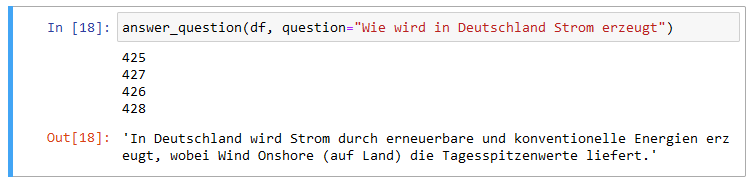
Wie wird in Deutschland Strom erzeugt?
Sämtliche referenzierten Textblöcke stammen aus dem Artikel Stromerzeugung in Deutschland. Dass Wind Onshore (auf Land) die Tagesspitzenwerte liefert, ist zwar im Kontext des Artikels richtig, gilt aber nur für den dort betrachteten Zeitraum vom 1.3. bis zum 18.4.2022. Anhand eines einzigen Artikels kann ChatGPT die allgemeingültigen nicht von den spezifischen Eigenschaften unterscheiden.
Auf eine Frage wie “Welche Textbausteine (ID) behandeln Strom in Deutschland?” erhält man innerhalb von ChatGPT zur Zeit noch keine vernünftige Antwort, da diese Meta-Information nicht in den Texten selbst steht.
Man könnte bei unserem Ansatz den Kontext um die Information der Quelle ergänzen, zum Beispiel beim Erstellen des Kontexts jedem Textblock ein “Textblock i enthält:” mit dem zugehörigen i voranstellen. Eine Frage wie “Comparator einsetzen, welche Textblöcke?” würde dann direkt von ChatGPT beantwortet werden, wenn auch im folgenden Beispiel unvollständig:
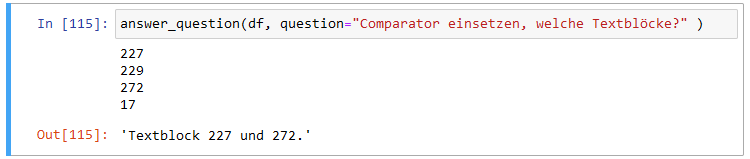
Comparator einsetzen, welche Textblöcke?
Natürlich könnte man die Information über die verwendeten Bausteine auch in der äußeren Python-Schleife erfassen und damit die gelieferte Antwort von ChatGPT anreichern:

Wozu ist der Publisher da?
Anstelle der IDs kann man sich auch Links zu den Artikeln denken.
Fine-tuning
Eine weitere Möglichkeit, eigene Texte zu verarbeiten, besteht im Fine-tuning. Dazu muss man zu jedem Text eine lange Liste von Prompt-Completion-Paaren aufstellen. Dabei gibt man selbst die gewünschte Antwort (Completion) auf eine gestellte Frage (Prompt) an. Open AI spricht von mindestens mehreren Hundert Paaren (siehe Preparing your dataset), mit denen ein bestehendes Modell nachtrainiert werden soll, um hier annehmbare Ergebnisse zu erzielen.
Das heißt, dass hier einiger Aufwand betrieben werden muss, um vernünftige Resultate zu erhalten.
Möglicherweise hilft ChatGPT bei der Aufgabe:

ChatGPT erstellt die Prompt-Completion-Paare
Die hier grün unterlegte Antwort von ChatGPT liefert schon einmal fünf Paare zu dem kurzen genannten Textabschnitt. Bei obigem Beispiel sind die ersten vier Vorschläge brauchbar, der letzte aber nicht. Oft muss händisch nachgebessert werden.
Prompt-Completion-Paare
Nichtsdestotrotz habe ich einmal mit dieser Methode für Textblöcke ab Mai 2022 Prompt-Completion-Paare erzeugen lassen und unbearbeitet im gelieferten Zustand gelassen. Mit diesen ca. 460 Paaren im JSONL-Format wurde dann das Modell (Variante Curie) weitertrainiert, sodass nun eine ChatGPT-Variante zur Verfügung steht, die nicht nur allgemeine Fragen zu allen möglichen Themen, sondern auch spezielle Fragen zu den Blogbeiträgen beantworten kann (soweit die Theorie).
Dabei muss nun kein Kontext geliefert werden. Man hat effektiv die Wissensbasis von ChatGPT erweitert.
Eines der 460 Paare ist beispielsweise das folgende:
- prompt: “Wie wird der Geschäftsklimaindex berechnet?”
- completion: ” aus Einschätzungen der Unternehmen zu ihrer eigenen Lage und der voraussichtlichen Entwicklung”
Stellen wir diese Frage einmal dem allgemeinen Modell, das unsere Texte nicht kennt, und anschließend dem mit den 460 Paaren feingetunten Modell:
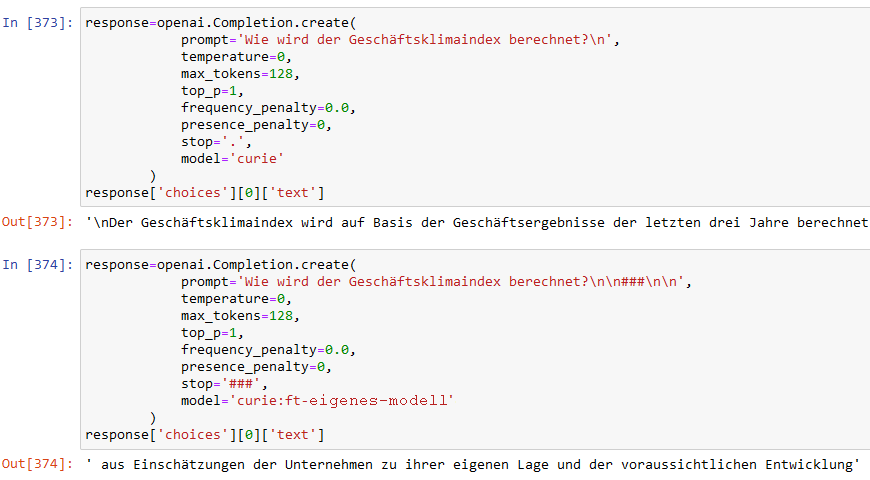
Das feingetunte Modell kennt die gewünschte Antwort
Das allgemeine Modell (“curie”) erzählt Nonsens, aber unser Modell gibt die gewünschte Antwort. Dabei mussten wir keinen Kontext übergeben und auch nicht mehr die Originaltexte vorhalten: Die Intelligenz steckt nun im angereicherten Modell!
So einwandfrei klappt das aber nicht immer und leichte Abwandlungen der Frage können auch zu von der Vorgabe abweichenden Ergebnissen führen:
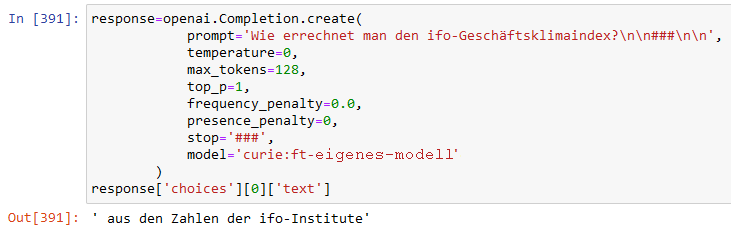
Das feingetunte Modell nennt hier nicht die gewünschte Antwort
Hier gerät ChatGPT möglicherweise in die Antwort eines verwandten Prompt-Completion-Paars:
- prompt: “Wie werden die Salden berechnet?”
- completion: ” aus den Zahlen des ifo-Instituts”
Das Thema bleibt spannend und sicherlich werde ich es in einem späteren Blog-Beitrag wieder aufgreifen.
Bissantz Talks
Wenn Sie mehr über KI im Umfeld von Business Intelligence erfahren wollen, empfehle ich Roboter hören die Musik nicht aus der Reihe Bissantz Talks am 6. Juni 2023, 16:00 – 16:20 Uhr.
Quellen
- Tutorial How to build an AI that can answer questions about your website
- ChatGPT zum Testen: chat.openai.com (nach Anmeldung)
- ChatGPT Playground (nach Anmeldung)
- API reference
