Wenn es im täglichen Geschäft darum geht, die richtigen Maßnahmen zu ergreifen, können gesammelte historische Daten wertvolle Erkenntnisse liefern. Jedoch ist bei der Auswertung Vorsicht geboten, möchte man nicht die falschen Schlüsse ziehen!
Im Zeitalter von Big Data wird dem Anwender oft der Eindruck vermittelt, dass das ausdauernde Sammeln von Daten bereits aus sich heraus den Weg zur Lösung eines Problems ebnet. Besonders dann, wenn es sich nicht um kontrolliert erhobene, sondern rein beobachtete Daten handelt, kann es jedoch passieren, dass selbst noch so viele Gigabyte nicht zu der benötigten Erkenntnis führen, solange eine Einbettung in ein passendes Modell fehlt.
Nehmen wir dazu einmal an, dass ein Zeitungsverlag die Kundenbindung optimieren möchte. Das Abonnement der zu untersuchenden Zeitschrift läuft immer für ein Jahr und wird dann hoffentlich vom Kunden verlängert.
In Abhängigkeit der bisherigen Laufzeit des Abonnements wurden bisher entweder keine Maßnahmen ergriffen, kurz vor Ablauf Erinnerungen verschickt oder sogar mit der Erinnerung Treueprämien versprochen.
Die Vorgehensweise lässt sich in einem Kausaldiagramm illustrieren:
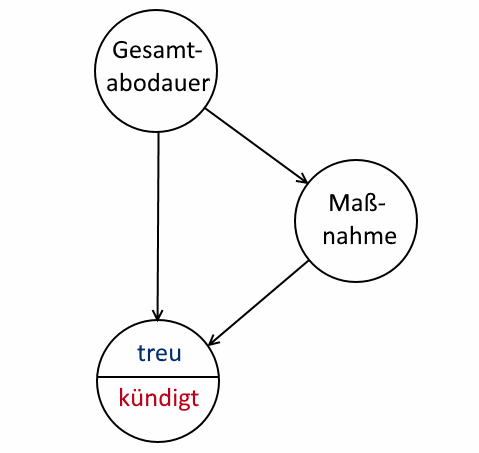
Kausaldiagramm
In diesem Diagramm wird angenommen, dass sich aus der bisherigen Abodauer mögliche Maßnahmen ableiten lassen. Die gewählte Maßnahme und die gegebene Gesamtabodauer bestimmen dann die
Wahrscheinlichkeit einer Aboverlängerung.
In der Realität können natürlich deutlich mehr Einflussgrößen vorliegen, aber wie wir gleich sehen werden, besitzt selbst dieses einfache Beispiel Hürden, die es zu überwinden gilt.
In unserem Beispiel wurden drei Klassen „Abo = 1“, „1 < Abo <= 5″ und “Abo > 5″ gebildet, die sich aus der bisherigen Abodauer in Jahren ableiten lassen.
Die Maßnahmen wurden bisher den Klassen nicht deterministisch zugeordnet, sondern über verschieden gewählte, dem Sachbearbeiter bekannte Wahrscheinlichkeiten zufällig ausgewählt. Die folgende Tabelle fasst diese Wahrscheinlichkeiten zusammen:

Zu jeder Abodauer gehört eine passende Maßnahmengewichtung
Aus dieser Tabelle lässt sich beispielsweise ablesen, dass langjährige Kunden bei der bisherigen Strategie häufiger durch eine Treueprämie belohnt werden. Diese Prämie wurde für relativ frische Kunden selten vergeben, beim überwiegenden Anteil (70 %) der 1-Jahres-Kunden wurde gar nichts unternommen.
Auch kein Geheimnis sind die Anteile der Abogruppen: Es wurde beobachtet, dass etwa 20 % der Kunden eine Abodauer von 1 Jahr haben, 30 % sind bis zu 5 Jahre Abonnenten und die Hälfte der Kunden, also 50 % halten schon seit über 5 Jahren die Treue.
Sei nun angenommen, dass die hypothetische Frage im Raume stehe, wie sich die Treuequoten der Aboverlängerer wohl entwickeln mögen, wenn von nun an entweder alle Kunden die Treueprämie erhielten, bzw. alternativ nur benachrichtigt oder sogar überhaupt nicht informiert würden.
Die Versuchung ist groß, mit der bedingten Wahrscheinlichkeit
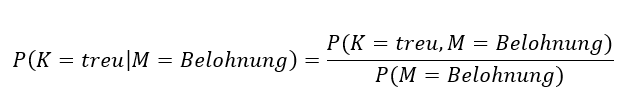
Treuer Kunde, gegeben eine Belohnung
zu arbeiten. Diese drückt die Wahrscheinlichkeit aus, einen treuen Kunden zu beobachten, unter der Nebenbedingung, dass er die Belohnung erhalten hatte. Diese theoretischen Werte lassen sich mit den vorliegenden Daten schätzen:
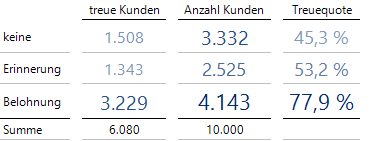
77.9 % der Kunden mit Belohnung waren treu
Satte 77.9 % der Kunden, die eine Belohnung erhalten haben, blieben treu. Heißt das, dass wir 77.9 % der Kunden halten können, wenn wir ab jetzt allen Kunden eine Prämie geben? Die Antwort lautet nein!
Es ist leider so, dass gemeinsame Wahrscheinlichkeitsfunktionen mehrerer Variablen von Natur aus erst einmal keine Information über Kausalität enthalten. Ob X das Y beeinflusst oder Y das X oder beide von einem unbekannten Z beeinflusst werden, lässt sich der gemeinsamen Wahrscheinlichkeitsfunktion und somit auch den bedingten Wahrscheinlichkeiten nicht ansehen.
Es gibt einen logischen Unterschied, ob ich einen Wert Y = y erhalte, während ein Wert X = x beobachtet wurde, oder ob ich X aktiv auf einen Wert x setze und dann schaue, welchen Wert Y annimmt. Judea Pearl verwendet in seinem Werk „Causality“ von 2009 den do-Operator, der mit do(X = x) angibt, dass ein Wert X aktiv auf x gesetzt wurde.
Es gilt somit im Allgemeinen bis auf vereinzelte Ausnahmen:
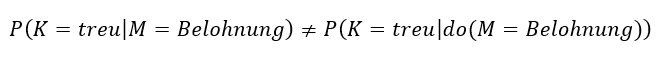
Einen Variablenwert zu beobachten ist nicht dasselbe wie ihn zu erzwingen!
Vielleicht hilft das folgende Beispiel dem Verständnis, dass die bedingte Wahrscheinlichkeit nicht die gesuchte Größe ist.
Seien sämtliche Maßnahmen gänzlich ohne Effekt, d. h., dass unabhängig von der Maßnahme jede der Abogruppen mit einer gewissen gruppenabhängigen Wahrscheinlichkeit kündigt. Für das Kausaldiagramm bedeutet dies, dass zwar die Maßnahmen noch von der Abodauer abhängen dürfen, aber der Einflusspfeil der Maßnahme auf die Treue nicht existiert:
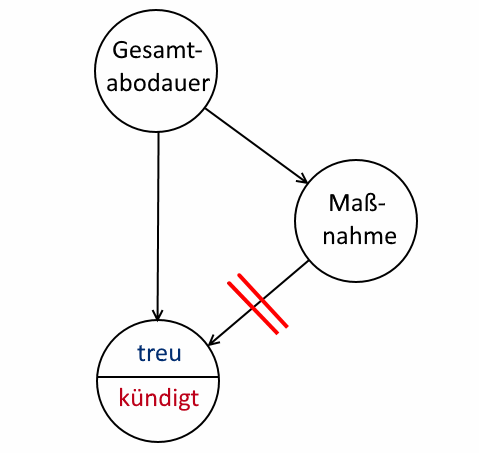
Wenn Maßnahmen verpuffen…
Seien wie bisher die Anteile der Gruppen 20 %, 30 % und 50 %. In der ersten Gruppe „Abo = 1“ sei die Treuequote 10%, in der zweiten Gruppe „1 < Abo <=5 ” 50% und in der dritten Gruppe “Abo > 5″ sei die Treuequote 90 %:

Berechnung der Wahrscheinlichkeit für einen treuen Kunden
Dies bedeutet nun, dass unabhängig von der für alle Kunden gewählten Maßnahme, die Wahrscheinlichkeit, einen treuen Kunden zu erhalten, 0.62 = 62 % beträgt:
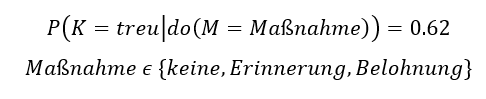
Wir könnten sogar für jeden einzelnen Kunden eine Maßnahme zuordnen – da sie keinen Einfluss hat, bleibt der Wert 0.62 unverändert. Nicht unverändert bleiben aber die bedingten Wahrscheinlichkeiten.
Seien dazu zwei besondere Strategien genannt: Bei der ersten erhalten nur die „Abo > 5“-Kunden die Belohnung. Von diesen Kunden werden mir aber 90 % die Treue halten, d. h., die bedingte Wahrscheinlichkeit P(K = treu| M = Belohnung) wird ebenfalls 0.9 betragen.
Im zweiten extremen Fall gebe ich die Belohnung nur den „Abo = 1“-Kunden. Nun werden 10 % der belohnten Kunden dabeibleiben, d. h. P(K = treu| M = Belohnung) beträgt in diesem Fall 0.1.
Die beiden genannten Werte widersprechen sich und somit kann der Wert P(K = treu| M = Belohnung) nicht dem gesuchten, eindeutigen Wert P(K = treu| do(M = Belohnung)) entsprechen.
Solche verzwickten Situationen treten immer dann auf, wenn die verordnete Medizin nahezu eins zu eins am Symptom ausgerichtet ist: Hinterher lässt sich nicht mehr auseinanderhalten, ob die Krankheit zu diesem Symptom gar nicht so schlimm war oder ob die Medizin geholfen hat.
Im ersten Fall in unserem Fallbeispiel könnte fälschlicherweise vermutet werden, dass die Belohnung hilft, da ja 90 % treue Kunden entstehen. In Wirklichkeit lag die hohe Treuequote aber nur an der langen Abodauer und die zugewiesene Maßnahme hatte überhaupt keinen Effekt!
Deshalb wird bei Versuchsreihen, wann immer es geht, randomisiert.
Bei Daten aus dem täglichen Geschäftsleben gibt es jedoch immer wieder Variablen, die nur beobachtet und nicht kontrolliert werden können, wie beispielsweise das Wetter.
Judea Pearl unterscheidet drei Ebenen der Komplexität: In der ersten werden gemeinsame Verteilungen von Größen beschrieben, die sich durch Beobachten schätzen lassen. Hierzu gehören auch Korrelationen wie „höherer Rabatt tritt eher mit höherem Umsatz auf“ oder „aggressive Kinder schauen länger Fernsehen“.
In der zweiten Komplexitätsebene wird untersucht, was passieren wird, wenn in das System eingegriffen wird, durch sogenannte Interventionen, wie etwa „Wenn ich den Rabatt jetzt erhöhe, wird sich der Umsatz erhöhen und wenn ja, um wie viel?“ oder „Wird der Fernsehkonsum reduziert, verringert sich dann auch die Aggressivität?“
Unser Beispiel in diesem Blog benutzt Aussagen dieser zweiten Ebene.
Die höchste Ebene beschäftigt sich mit sogenannten Counterfactuals (Kontrafaktuale). Hier ist das Kind schon in den Brunnen gefallen und ich frage danach, zu welchem Ergebnis eine andere Entscheidung in der Vergangenheit geführt hätte. Beispiele sind „Wäre bei diesem Kunden der Umsatz auch erhöht, wenn ich keinen Rabatt gegeben hätte?“ oder „Wäre Edwin Hardeman nicht an Krebs erkrankt, hätte er keinen Kontakt mit dem Unkrautvernichtungsmittel Roundup gehabt?“ oder „Hätte ich nicht schon längst den Supermarkt verlassen können, wenn ich die andere Schlange gewählt hätte?“.
Kehren wir zurück zu unserem ursprünglichen Beispiel. Da wir nun wissen, dass bedingte Wahrscheinlichkeiten allein nicht zur Vorhersage von Interventionen geeignet sind, müssten wir eigentlich Trübsal blasen.
Zur Erinnerung: Die hier zu lösende Aufgabe aus dem Bereich der Predictive Analytics ist, aufgrund nur beobachteter Werte vorhersagen zu können, welchen Einfluss die Fixierung einer Maßnahme für alle Kunden auf die Gesamttreuequote haben wird.
Wiederum Judea Pearl hat gezeigt, dass es oft möglich ist, aus dem Graphen Kriterien und Formeln abzuleiten, die sicherstellen, dass der Effekt einer Intervention unverfälscht geschätzt werden kann. Hier bei unserem einfachen Graphen ist das möglich und es gilt:
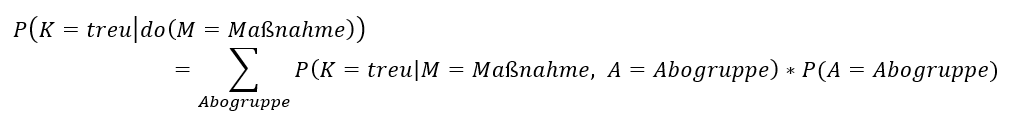
Interventionsformel
Wenn also die Graphenstruktur „stimmt“ und der Wirklichkeit entspricht und die entscheidenden Knoten des Graphen auch bekannt sind, wird das Problem aus der zweiten Komplexitätsebene „Auswirkung einer Intervention“ (linke Seite der Formel) auf einen Ausdruck der ersten Komplexitätsebene zurückgeführt (rechte Seite der Formel) – und die Ausdrücke der rechten Seite lassen sich durch reines Beobachten schätzen!
Wir führen nun in DeltaMaster diese Schätzung durch: Treuequote schätzt den ersten Faktor in der Summe, Anteil Abogruppe den zweiten Faktor und Beitrag ist das Produkt dieser beiden Größen. Pro Maßnahme ist die Summe der Beiträge über die Abogruppen gesucht; hier verwenden wir der Einfachheit halber die Spaltenaggregation.
Die Anwendung der nützlichen Small Multiples ergibt:
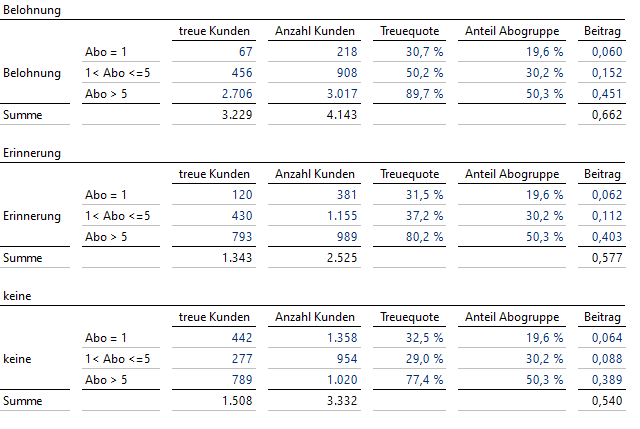
Interventionsformel angewandt
Die Summe der Werte von „Beitrag“ zeigt: Werden alle Kunden belohnt, so sollten 66.2 % treue Kunden entstehen – und nicht die zu optimistischen 77.9 % mit der falschen Formel der bedingten Wahrscheinlichkeit von oben.
Werden alle Kunden erinnert, liegt die geschätzte Quote bei 57.7 % und schließlich werden sich ca. 54 % treue Kunden ergeben, falls ab jetzt gar nichts mehr unternommen wird.
Da wir die Daten selbst erzeugt haben, lassen sich die theoretischen Werte exakt berechnen; sie betragen 0.66, 0.58 und 0.55, liegen somit dicht bei unseren Schätzern.
Sollten sich im Laufe der Zeit die Anteile der Abodauergruppen ändern, kann die Formel auch mit den aktuellen Anteilen verwendet werden.
Als Quintessenz bleibt zu konstatieren, dass reine Beobachtungen unter gewissen Annahmen ausreichen, um den Effekt von Interventionen abschätzen zu können.
Der kausale Graph darf auch ruhig komplexer sein. Es wird wieder angenommen, dass die Wahrscheinlichkeiten der Werte eines Knotens nur von den Werten der direkten Vorgängerknoten abhängen:
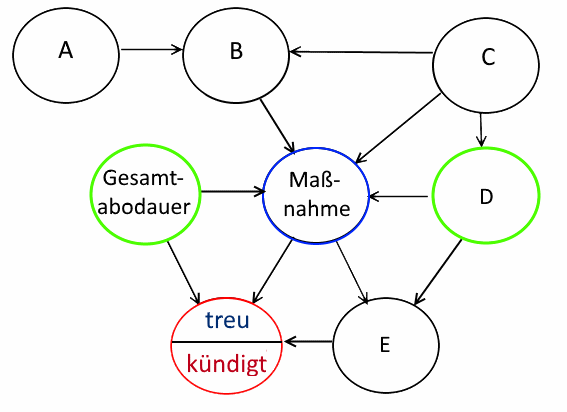
Komplexer Graph
Die Ermittlung der Knoten, die bei der Schätzung der Auswirkung einer Intervention bekannt sein müssen, ist eine Wissenschaft für sich, lässt sich aber nichtsdestotrotz automatisieren. Es kann dabei der Fall auftreten, dass es mehrere Möglichkeiten der Schätzung gibt. Ebenso können aber auch Graphen existieren, bei denen die Schätzung der Auswirkung einer Intervention allein aus Beobachtungen auf die beschriebene Weise nicht funktioniert, da die Werte der notwendigen Knoten nicht bekannt sind.
In diesem Beispiel würde es genügen, zusätzlich zur Gesamtabodauer noch die Variable D beobachten zu können, um den Effekt einer Änderung der Maßnahme nur aus beobachteten Daten schätzen zu können.
Um aber etwa den Effekt der Maßnahme „do (Maßnahme = Belohnung)“ beurteilen zu können, musste es natürlich in der Phase der Beobachtung auch Belohnungen gegeben haben; eine gänzlich neue Intervention lässt sich mit diesem Ansatz nicht vorhersagen!
Es lässt sich auch in einem gewissen Rahmen überprüfen, ob der vermutete Kausalgraph denn auch zur Wirklichkeit passt. Der letzte Graph würde beispielsweise induzieren, dass A und C oder auch A und Gesamtabodauer unabhängig sein müssen. Dies lässt sich anhand der Daten testen. Ebenso gibt es nachprüfbare Aussagen über bedingte Unabhängigkeit: Wenn beispielsweise D und die Maßnahme fixiert sind, müssen B und E unabhängig sein.
Literatur: Judea Pearl – Causality, Cambridge University Press; 2nd Revised edition 2009
Judea Pearl, Madelyn Glymour and Nicholas P. Jewell – Causal Inference in Statistics – A Primer, Wiley 2016.
Benito van der Zander et al., Constructing Separators and Adjustment Sets in Ancestral Graphs, Proceedings of the Thirtieth Conference on Uncertainty in Artificial Intelligence, UAI’14.

Kommentare
Sie müssten eingeloggt sein um Kommentare zu posten..